Introduction
At Qodo, we’ve created a new benchmark dataset of real-world questions derived from large, complex code repositories. We are excited to release the dataset, methodology, and prompts used in its creation to support further research and development.Motivation
Enterprises often maintain massive codebases that are difficult for any individual developer to navigate and fully understand. Whether onboarding, doing routine development, or using AI-assisted workflows, teams often have questions about their codebase. To effectively address this, we’ve developed specialized retrieval capabilities within our research agents. However, to benchmark and validate these systems effectively, we require a robust set of real-world questions and answers.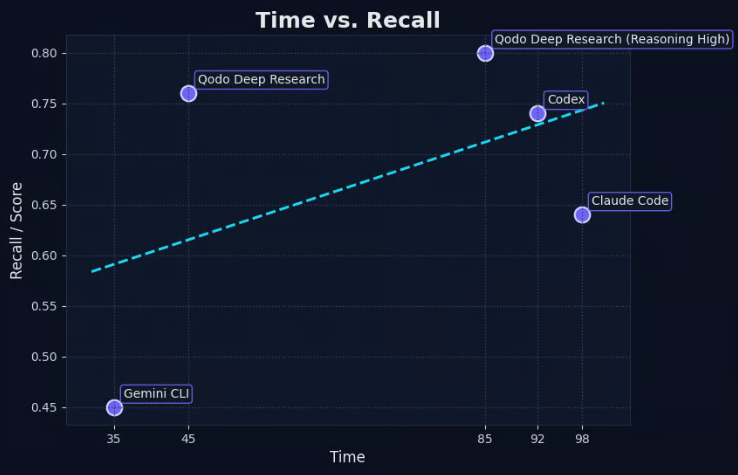
| Agent | Time | Score |
|---|---|---|
| 🥇 Qodo deep-research (Reasoning high) | 45 | 0.76 |
| Codex | 92 | 0.74 |
| Claude Code | 98 | 0.64 |
| Gemini cli | 35 | 0.45 |